This is the multi-page printable view of this section. Click here to print.
Architecture
The Architecture Of ESA RestClient

ESA Stack(Elastic Service Architecture) 是OPPO云计算中心孵化的技术品牌,致力于微服务相关技术栈,帮助用户快速构建高性能,高可用的云原生微服务。产品包含高性能Web服务框架、RPC框架、服务治理框架、注册中心、配置中心、调用链追踪系统,Service Mesh、Serverless等各类产品及研究方向。
当前部分产品已经对外开源:
Github: https://github.com/esastack
RestClient 项目地址:https://github.com/esastack/esa-restclient
RestClient 文档地址:https://www.esastack.io/esa-restclient
欢迎各路技术爱好者们加入,一同探讨学习与进步。
ESA RestClient
ESA RestClient 是一个基于 Netty 的全链路异步事件驱动的高性能轻量级的HTTP客户端。
以下简称RestClient
1. Quick Start
Step1:添加依赖
<dependency>
<groupId>io.esastack</groupId>
<artifactId>restclient</artifactId>
<version>1.0.0</version>
</dependency>
Step2: 构建RestClient并发送请求处理响应
final RestClient client = RestClient.ofDefault(); //快速创建RestClient,各项配置均为默认配置。
//如果用户想自定义一些配置,则可以使用RestClient.create()来进行自定义配置。
client.post("http://127.0.0.1:8081/")
.entity("Hello Server") //设置请求体
.execute() //执行请求逻辑
.thenAccept((response)-> { //异步处理响应
try {
System.out.println(response.bodyToEntity(String.class)); //调用response.bodyToEntity(Class TargetClass)来 Decode 响应,
//TargetClass为期望的响应类型
} catch (Exception e) {
e.printStackTrace();
}
});
2. 功能特性
- Http1/H2/H2cUpgrade/Https
- Encode 与 EncodeAdvice
- Decode 与 DecodeAdvice
- RestInterceptor
- 大文件发送
- 请求级别读超时
- 请求级别重试
- 请求级别重定向
- 100-expect-continue
- Multipart
- Metrics
- more …
2.1 Encode 与 EncodeAdvice
2.1.1 Encode
RestClient会自动根据用户的 Headers 与 Entity 等选择合适的Encoder进行Encode。其内置了下面这些Encoder:
- Json
- jackson(默认)
- fastjson
- gson
- ProtoBuf
- File
- String
- byte[]
除此之外
RestClient也支持用户自定义Encoder。
2.1.1.1 使用Json Encoder
指定contentType为MediaType.APPLICATION_JSON,将自动使用Json Encoder来对Entity来进行Encode。示例如下:
final RestClient client = RestClient.ofDefault();
client.post("localhost:8080/path")
.contentType(MediaType.APPLICATION_JSON)
.entity(new Person("Bob","male"))
.execute();
2.1.1.2 使用ProtoBuf Encoder
指定contentType为ProtoBufCodec.PROTO_BUF,且Entity类型为com.google.protobuf.Message的子类时,将自动使用ProtoBuf Encoder来对Entity来进行Encode。示例如下:
final RestClient client = RestClient.ofDefault();
client.post("localhost:8080/path")
.contentType(ProtoBufCodec.PROTO_BUF)
.entity(message)
.execute();
2.1.1.3 使用File Encoder
当Entity类型为File时,将自动使用File Encoder来对Entity来进行Encode。示例如下:
final RestClient client = RestClient.ofDefault();
client.post("localhost:8080/path")
.entity(new File("tem"))
.execute();
2.1.1.4 自定义Encoder
当RestClient内置的Encoder无法满足用户需求时,用户可以自定义Encoder,示例如下:
public class StringEncoder implements ByteEncoder {
@Override
public RequestContent<byte[]> doEncode(EncodeContext<byte[]> ctx) {
if (MediaType.TEXT_PLAIN.equals(ctx.contentType())) {
if (ctx.entity() != null) {
return RequestContent.of(((String) ctx.entity()).getBytes(StandardCharsets.UTF_8));
} else {
return RequestContent.of("null");
}
}
//该Encoder无法Encode这种类型,将Encode工作交给下一个Encoder
return ctx.next();
}
}
用户可以将自定义的Encoder直接绑定到请求或者Client上,同时也支持用户通过SPI的方式加载Encoder,具体参见文档:《RestClient 配置Encoder》
2.1.1.5 Encode执行时机
见请求处理完整流程中的Encoder。
2.1.2 EncodeAdvice
用户可以通过EncodeAdvice在Encode前后插入业务逻辑,来对要Encode的 Entity 或者 Encode后的RequestContent 进行修改替换等操作。
2.1.2.1 示例
public class EncodeAdviceImpl implements EncodeAdvice {
@Override
public RequestContent<?> aroundEncode(EncodeAdviceContext ctx) throws Exception {
//...before encode
RequestContent<?> requestContent = ctx.next();
//...after encode
return requestContent;
}
}
用户可以将自定义的EncodeAdvice直接绑定到Client上,同时也支持用户通过SPI的方式加载EncodeAdvice,具体参见文档:《RestClient 配置EncodeAdvice》
2.1.2.2 执行时机
见请求处理完整流程中的EncodeAdvice。
2.2 Decode 与 DecodeAdvice
2.2.1 Decode
RestClient会自动根据用户的 Headers 与 期望Entity类型 等选择合适的Decoder进行Decode。RestClient内置了下面这些Decoder:
- Json
- jackson(默认)
- fastjson
- gson
- ProtoBuf
- String
- byte[]
除此之外
RestClient也支持用户自定义解码器。
2.2.1.1 使用Json Decoder
当Response的contentType为MediaType.APPLICATION_JSON,将自动使用Json Decoder来来进行Decode。
final RestClient client = RestClient.ofDefault();
client.get("localhost:8080/path")
.execute()
.thenAccept((response)-> {
try {
//当 MediaType.APPLICATION_JSON.equals(response.contentType()) 时将自动使用Json Decoder
System.out.println(response.bodyToEntity(Person.class));
} catch (Exception e) {
e.printStackTrace();
}
});
2.2.1.2 使用ProtoBuf Decoder
当Response的contentType为ProtoBufCodec.PROTO_BUF,且response.bodyToEntity()传入的类型为com.google.protobuf.Message的子类时,将自动使用ProtoBuf Decoder来进行Decode。
final RestClient client = RestClient.ofDefault();
client.get("localhost:8080/path")
.execute()
.thenAccept((response)-> {
try {
//当 ProtoBufCodec.PROTO_BUF.equals(response.contentType()),且 Person 为 Message 的子类时,将自动使用ProtoBuf Decoder
System.out.println(response.bodyToEntity(Person.class));
} catch (Exception e) {
e.printStackTrace();
}
});
2.2.1.3 自定义Decoder
当RestClient内置的Decoder无法满足用户需求时,用户可以自定义Decoder,示例如下:
public class StringDecoder implements ByteDecoder {
@Override
public Object doDecode(DecodeContext<byte[]> ctx) {
if (String.class.isAssignableFrom(ctx.targetType())) {
return new String(ctx.content().value());
}
return ctx.next();
}
}
用户可以将自定义的Decoder直接绑定到请求或者Client上,同时也支持用户通过SPI的方式加载Decoder,具体参见文档:《RestClient 配置Decoder》
2.2.1.4 执行时机
见请求处理完整流程中的Decoder。
2.2.2 DecodeAdvice
用户可以通过DecodeAdvice在Decode前后进行来插入业务逻辑,来对要解码的 ResponseContent 或者 Decode后的对象 进行修改替换等操作。
2.2.2.1 示例
public class DecodeAdviceImpl implements DecodeAdvice {
@Override
public Object aroundDecode(DecodeAdviceContext ctx) throws Exception {
//...before decode
Object decoded = ctx.next();
//...after decode
return decoded;
}
}
用户可以将自定义的DecodeAdvice直接绑定到Client上,同时也支持用户通过SPI的方式加载DecodeAdvice,具体参见文档:《RestClient 配置DecodeAdvice》
2.2.2.2 执行时机
见请求处理完整流程中的DecodeAdvice。
2.3 RestInterceptor
用户可以使用RestInterceptor在请求发送前和响应接收后来插入业务逻辑。RestClient支持通过builder配置和SPI加载两种方式配置RestInterceptor。
2.3.1 Builder配置
在构造RestClient时传入自定义的RestInterceptor实例,如:
final RestClient client = RestClient.create()
.addInterceptor((request, next) -> {
System.out.println("Interceptor");
return next.proceed(request);
}).build();
2.3.2 SPI
2.3.2.1 普通SPI
RestClient支持通过SPI的方式加载RestInterceptor接口的实现类,使用时只需要按照SPI的加载规则将自定义的RestInterceptor放入指定的目录下即可。
2.3.2.2 RestInterceptorFactory
如果用户自定义的RestInterceptor对于不同RestClient的配置有不同的实现,则用户可以实现RestInterceptorFactory接口,并按照SPI的加载规则将自定义的RestInterceptorFactory放入指定的目录下即可。
public interface RestInterceptorFactory {
Collection<RestInterceptor> interceptors(RestClientOptions clientOptions);
}
在RestClient构建时将调用RestInterceptorFactory.interceptors(RestClientOptions clientOptions),该方法返回的所有RestInterceptor都将加入到构建好的RestClient中。
2.3.2.3 执行时机
见请求处理完整流程中的RestInterceptor。
2.4 大文件发送
当文件较小时,可通过直接将文件内容写入请求body来发送文件。但是当文件内容过大时,直接写入会有OOM风险。
为了解决这个问题,RestClient借助底层的Netty使用NIO以零拷贝的方式发送文件,避免了OOM的同时又减少了数据的多次拷贝。
用户只需要简单的接口调用便可使用该功能:
final RestClient client = RestClient.ofDefault();
final String entity = client.post("http://127.0.0.1:8081/")
.entity(new File("bigFile"))
.execute();
2.5 读超时
RestClient支持请求级别的读超时,同时也支持Client 级别的读超时。默认读超时为6000L。
2.5.1 Client级别读超时
Client级别的读超时将对该Client下的所有请求生效,具体配置方式如下:
final RestClient client = RestClient.create()
.readTimeout(3000L)
.build();
2.5.2 Request级别读超时
当Request设置了读超时,其数据将覆盖Client设置的读超时,具体配置方式如下:
final RestClient client = RestClient.ofDefault();
client.get("http://127.0.0.1:8081/")
.readTimeout(3000L)
.execute()
.thenAccept((response)-> {
try {
System.out.println(response.bodyToEntity(String.class));
} catch (Exception e) {
e.printStackTrace();
}
});
2.6 重试
RestClient支持请求级别的重试,同时也支持Client 级别的重试。
默认情况下,RestClient仅会对所有抛出连接异常的请求进行重试(防止服务端的服务为非幂等),其中:最大重试次数为3(不包括原始请求),重试间隔时间为0。使用时,可以通过自定义RetryOptions参数更改重试次数、重试条件、重试间隔时间等。
2.6.1 Client级别重试
Client级别的重试将对该Client下的所有 Request 生效,使用时,可以通过自定义RetryOptions参数更改重试次数、重试条件、重试间隔时间等。具体配置方式如下:
final RestClient client = RestClient.create()
.retryOptions(RetryOptions.options()
.maxRetries(3)
//设置每次重试的间隔时间
.intervalMs(retryCount-> (retryCount+1) * 3000L)
//判断是否要重试
.predicate((request, response, ctx, cause) -> cause != null)
.build())
.connectionPoolSize(2048)
.build();
2.6.2 Request级别重试
当Request设置了重试次数,其数据将覆盖Client设置的重试次数,具体配置方式如下:
final RestClient client = RestClient.ofDefault();
client.get("http://127.0.0.1:8081/")
.maxRetries(3)
.execute()
.thenAccept((response)-> {
try {
System.out.println(response.bodyToEntity(String.class));
} catch (Exception e) {
e.printStackTrace();
}
});
2.7 重定向
默认情况下,RestClient会对响应状态码为301,302,303,307,308的请求重定向,其中:最大重定向次数为5(不包含原始请求)。使用时,可以通过maxRedirects更新重定向次数或者禁用(maxRedirects=0)重定向功能。
2.7.1 Client设置重定向
Client级别的重定向将对该Client下的所有 Request 生效,具体配置方式如下:
final RestClient client = RestClient.create()
.maxRedirects(3)
.build();
2.7.2 Request设置重定向覆盖Client的设置
当Request设置了重定向次数,其数据将覆盖Client设置的重定向次数,具体配置方式如下:
final RestClient client = RestClient.ofDefault();
client.get("http://127.0.0.1:8081/")
.maxRedirects(3)
.execute()
.thenAccept((response)-> {
try {
System.out.println(response.bodyToEntity(String.class));
} catch (Exception e) {
e.printStackTrace();
}
});
2.8 其它功能
如果用户想对RestClient的功能有进一步了解,可以参考:《RestClient 功能文档》。
3 性能表现
3.1 测试场景
服务端为一个Echo服务器,客户端分别使用RestClient、Apache HttpAsyncClient 、 OK Httpclient均使用POST请求,请求体内容为固定字符串: OK,响应体内容也为固定字符串:OK。
3.2 机器配置
| OS | 内存(G) | CPU核数 | |
|---|---|---|---|
| Client | CentOS Linux release 7.7.1908 (Core) | 8 | 4 |
| Server | CentOS Linux release 7.7.1908 (Core) | 16 | 8 |
3.3 JVM参数
-Xms1024m -Xmx1024m -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=256m -XX:+UseConcMarkSweepGC -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=70
3.4 客户端版本
| 客户端 | RestClient | Apache HttpAsyncClient | OK HttpClient |
|---|---|---|---|
| 版本 | 1.0.0 | 5.1.2 | 4.9.2 |
3.5 测试方法
如何测试异步客户端的性能?这是我们在性能测试前要面对的第一个问题,下面是我们对于该问题的一些思考:
能否for循环发起同步请求,同时使用多线程来达到框架的请求处理极限,并将该极限视为客户端的最佳TPS?
一般来说,用户既然选择异步客户端,肯定大部分时间都会使用异步的方式去发起请求,使用同步方式进行测试的结果并不能代表异步时客户端的性能。因此对于异步客户端的用户而言,同步方式测试的最终结果并没有很大的参考价值。
因此这种方式并不适合用来对异步客户端进行性能测试。 能否使用单线程for循环异步发起请求,直接将这个时候的TPS视为客户端的最佳TPS?
异步客户端异步发起请求时,发起请求的方法返回的非常快(因为请求执行的过程主要在IO线程池中进行)。尽管只使用单线程,如果一直for循环异步发起请求,请求发起的速度也会比IO线程池处理请求的速度快得多,这会导致大量请求在程序中的某个地方(如获取连接)堆积,从而导致程序报错,或性能低下。
因此这种方式也并不适合用来对异步客户端进行性能测试。 那么应该如何测试异步客户端的性能呢?
异步客户端专为异步而生,用户既然选择异步客户端,肯定大部分时间都会使用异步的方式发起请求,因此对于异步客户端而言,使用异步的方式去测试其性能是一种更加合适的方式。
问题的关键在于在测试过程中,如何避免过快地发起异步请求导致发起请求的速度超过框架的处理能力。
主要问题确定了,那么答案基本也就确定了。要避免过快地发起异步请求,我们可以想办法调整异步请求发起的速度,对于调整异步请求的发起速度,我们可以尝试用以下两种方式:
- for循环周期性地发送一定次数的异步请求后,sleep一会儿,然后再继续发起异步请求。我们可以通过 控制sleep的时间 和 控制多少个请求间隔进行sleep两个变量来控制异步请求的发起速率。
- for循环周期性地发送一定次数的异步请求后,发送一个同步请求,然后再继续发起异步请求。用同步请求去代替sleep的时间,该同步请求执行完恰好说明了请求队列中的请求都已经排队结束。其实原理是相同的,但这样控制的变量更少一些,仅需要控制发起多少个异步请求后发起一次同步请求(即:一个周期内异步请求次数与同步请求次数的比例)。 上面两种方法都可以控制异步请求的发起速率,最终我们选择使用第二种方法来控制异步请求的发起速率,因为第二种方式需要控制的变量更少,这样我们的测试过程也会更加简单。
因此最终我们的测试方法为:
使用异步与同步交替的方式来发起请求,不断调整一个周期内异步请求与同步请求的比例,在每个比例下调整客户端的各项配置,使其达到最佳的TPS,记录每个比例下,框架的最佳TPS,直到找到增加 异步请求与同步请求的比例 时,框架的TPS不再上升,甚至下降的拐点,该拐点即为框架的性能极限点。
3.6 测试结果
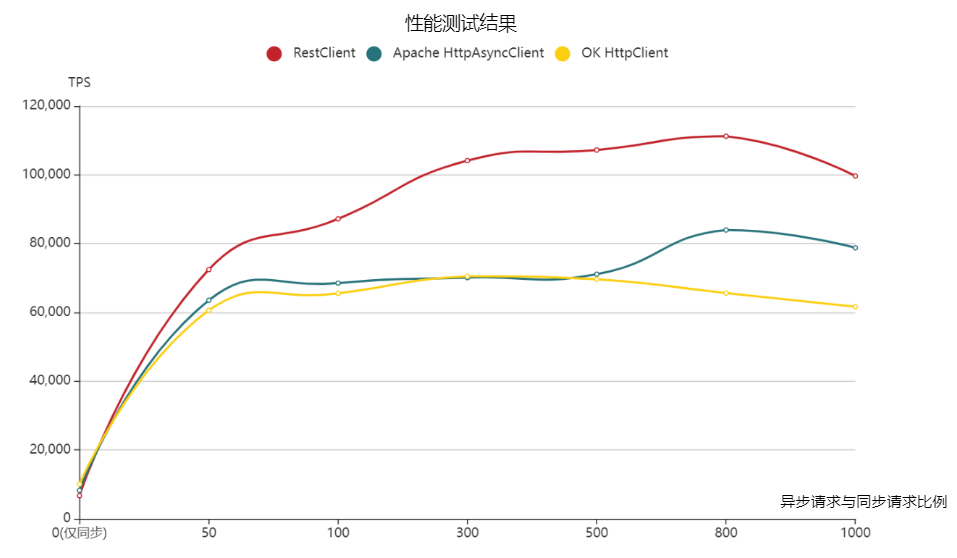
上图中,横坐标为异步请求与同步请求的比例,纵坐标为TPS,通过上图我们可以看出:
RestClient:随着异步与同步请求比例增大而先增大后减小,异步与同步请求比例为800时,TPS最佳,为111217.98。Apache HttpAsyncClient:随着异步与同步请求比例增大而先增大后减小,异步与同步请求比例为800时,TPS最佳,为 83962.54。OK Httpclient:随着异步与同步请求比例增大而先增大后减小,异步与同步请求比例为300 时,TPS最佳,为 70501.59。
3.7 结论
RestClient在上面场景中最佳TPS 较 Apache HttpAsyncClient的最佳TPS高 32%,较OK Httpclient的最佳TPS高57% 。
3.8 详细的测试数据
3.8.1 RestClient
| 异步与同步请求比例 | TPS | RT | 成功率 | 失败个数 | maxrt | minrt | 50rt | 90rt | 95rt | 99rt | client cpu * load |
|---|---|---|---|---|---|---|---|---|---|---|---|
| -1(仅同步) | 6727.32 | 0.15 | 100% | 0 | 164 | 0 | 0 | 1 | 1 | 1 | 96.0% |
| 50 | 72447.11 | 0.43 | 100% | 0 | 190 | 0 | 0 | 1 | 1 | 1 | 291.0% |
| 100 | 87201.45 | 0.64 | 100% | 0 | 182 | 0 | 1 | 1 | 1 | 2 | 326.7% |
| 300 | 104129.04 | 1.38 | 100% | 0 | 258 | 0 | 1 | 2 | 3 | 4 | 370.1% |
| 500 | 107217.98 | 2.18 | 100% | 0 | 241 | 0 | 2 | 4 | 4 | 6 | 376.7% |
| 800 | 111217.98 | 2.88 | 100% | 0 | 261 | 0 | 3 | 7 | 8 | 11 | 373.4% |
| 1000 | 99656.49 | 4.59 | 100% | 0 | 376 | 0 | 4 | 8 | 9 | 13 | 386.4% |
3.8.2 Apache HttpAsyncClient
| 异步与同步请求比例 | TPS | RT | 成功率 | 失败个数 | maxrt | minrt | 50rt | 90rt | 95rt | 99rt | client cpu * load |
|---|---|---|---|---|---|---|---|---|---|---|---|
| -1(仅同步) | 8257.91 | 0.12 | 100% | 0 | 88 | 0 | 0 | 1 | 1 | 1 | 91.0% |
| 50 | 63515.9 | 0.16 | 100% | 0 | 89 | 0 | 0 | 1 | 1 | 1 | 371.8% |
| 100 | 68515.9 | 0.21 | 100% | 0 | 90 | 0 | 0 | 1 | 1 | 2 | 389.7% |
| 300 | 70133.2 | 0.30 | 100% | 0 | 90 | 0 | 0 | 1 | 1 | 2 | 391.3% |
| 500 | 71101.49 | 0.37 | 100% | 0 | 89 | 0 | 0 | 1 | 1 | 2 | 393.1% |
| 800 | 83962.54 | 0.55 | 100% | 0 | 92 | 0 | 0 | 1 | 1 | 2 | 391.0% |
| 1000 | 78786.09 | 0.78 | 100% | 0 | 108 | 0 | 0 | 1 | 2 | 4 | 394.3% |
3.8.3 OK HttpClient
| 异步与同步请求比例 | TPS | RT | 成功率 | 失败个数 | maxrt | minrt | 50rt | 90rt | 95rt | 99rt | client cpu * load |
|---|---|---|---|---|---|---|---|---|---|---|---|
| -1(仅同步) | 10063.36 | 0.10 | 100% | 0 | 82 | 0 | 0 | 0 | 1 | 1 | 106.3% |
| 50 | 60600.31 | 0.42 | 100% | 0 | 69 | 0 | 0 | 1 | 1 | 1 | 400.0% |
| 100 | 65527.59 | 0.73 | 100% | 0 | 67 | 0 | 0 | 1 | 1 | 1 | 400.0% |
| 300 | 70501.59 | 1.93 | 100% | 0 | 73 | 0 | 0 | 1 | 1 | 1 | 400.0% |
| 500 | 69633.59 | 3.2 | 100% | 0 | 101 | 0 | 3 | 5 | 5 | 22 | 400.0% |
| 800 | 65631.21 | 3.6 | 100% | 0 | 104 | 0 | 4 | 7 | 9 | 28 | 400.0% |
| 1000 | 61633.31 | 4.1 | 100% | 0 | 112 | 0 | 6 | 8 | 12 | 38 | 400.0% |
4 架构设计
4.1 设计原则
- 高性能:持续不懈追求的目标 & 核心竞争力。
- 高扩展性:开放扩展点,满足业务多样化的需求。
- 全链路异步:基于
CompletableStage提供完善的异步处理能力。
4.2 结构设计
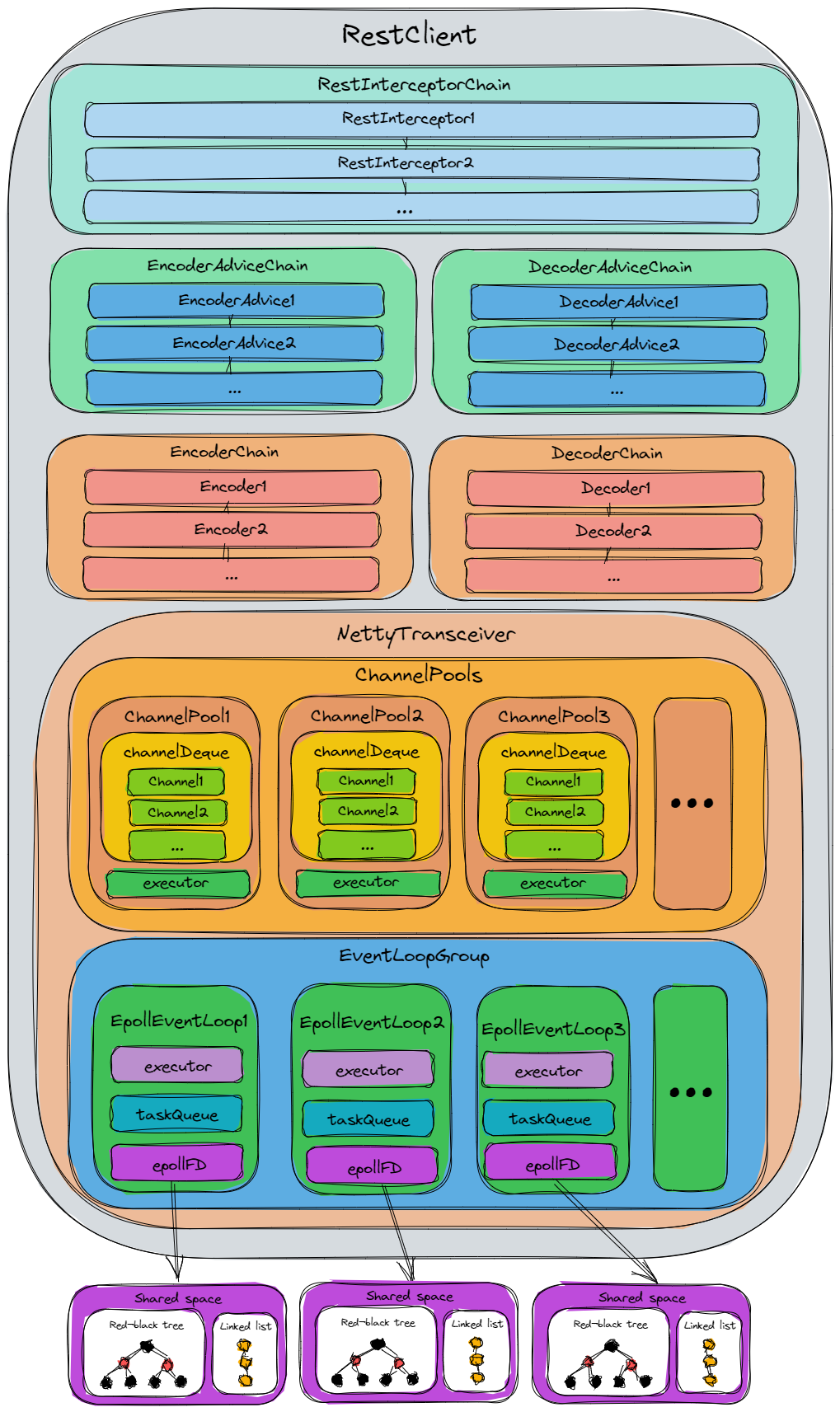
上图为RestClient的结构图,我们由上到下依次介绍一下各个部分的含义:
4.2.1 RestInterceptorChain
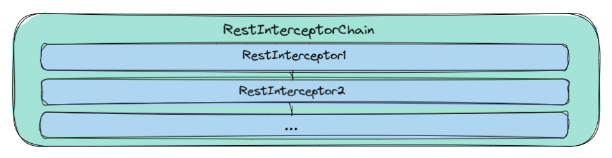
RestInterceptorChain为RestInterceptor的集合,用户调用请求时,将依次经过RestInterceptorChain中的所有RestInterceptor。用户可以通过实现RestInterceptor中的getOrder()方法来指定其在RestInterceptorChain中的排序。
4.2.2 EncodeAdviceChain
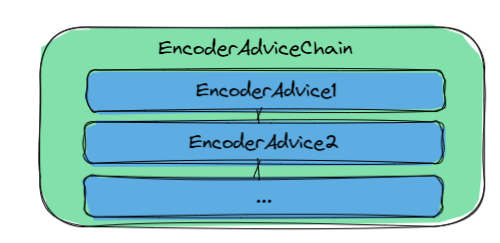
EncodeAdviceChain为EncodeAdvice的集合,在Encode前,将依次经过EncodeAdviceChain中的所有EncodeAdvice。用户可以通过实现EncodeAdvice中的getOrder()方法来指定其在EncodeAdviceChain中的排序。
4.2.3 EncoderChain
EncoderChain为Encoder的集合,在Encode时,将依次经过EncoderChain中的所有Encoder,直到某个Encoder直接返回Encode的结果(即:其可以Encode该请求)。用户可以通过实现Encoder中的getOrder()方法来指定其在EncoderChain中的排序。
4.2.4 DecodeAdviceChain
DecodeAdviceChain为DecodeAdvice的集合,在Decode前,将依次经过DecodeAdviceChain中的所有DecodeAdvice。用户可以通过实现DecodeAdvice中的getOrder()方法来指定其在DecodeAdviceChain中的排序。
4.2.5 DecoderChain
DecoderChain为Decoder的集合,在Decode时,将依次经过DecoderChain中的所有Decoder,直到某个Decoder直接返回Decode的结果(即:其可以Decode该响应)。用户可以通过实现Decoder中的getOrder()方法来指定其在DecoderChain中的排序。
4.2.6 NettyTransceiver
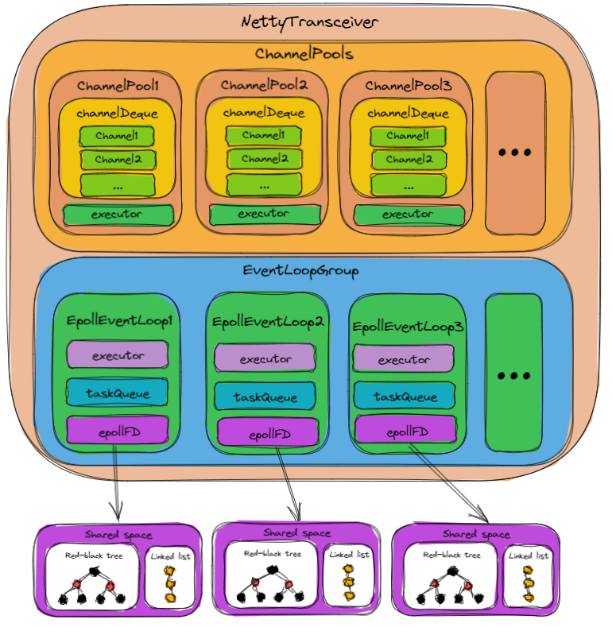
NettyTransceiver 是 RestClient与其底层框架Neety之间连接的桥梁,在介绍其之前,需要一些预备知识,我们先来简单介绍一下这些预备知识:
4.2.6.1 Channel & ChannelPool &ChannelPools
Channel : Channel是Netty网络操作抽象类,它聚合了一组功能,包括但不限于网络的读、写,客户端发起连接、主动关闭连接,链路关闭,获得通信双方的网络地址等。它也包含了Netty框架相关的一些功能,包括获取该Channel的EventLoop,获取缓冲分配器ByteBufAllocator和pipeline等。
ChannelPool:ChannelPool用于缓存Channel,它允许获取和释放Channel,并充当这些Channel的池,从而达到复用Channel的目的。在RestClient中,每一个Server host对应一个ChannelPool。
ChannelPools:ChannelPools用于缓存ChannelPool。在RestClient中,当一个Server host长时间没有被访问时,其所对应的ChannelPool将会被视作缓存过期,从而被回收资源。
4.2.6.2 EventLoop & EventLoopGroup
EventLoop:EventLoop在Netty中被用来运行任务来处理在Channel的生命周期内发生的事件。在RestClient中,一个EventLoop对应了一个线程。
EventLoopGroup:EventLoopGroup为一组EventLoop,其保证将多个任务尽可能地均匀地分配在多个EventLoop上。
4.2.6.3 Epoll
Epoll是Linux内核的可扩展I/O事件通知机制,包含下面这三个系统调用。
int epoll_create(int size);
在内核中创建epoll实例并返回一个epoll文件描述符(对应上图中 EpollEventLoop中的epollFD)。 在最初的实现中,调用者通过 size 参数告知内核需要监听的文件描述符数量。如果监听的文件描述符数量超过 size, 则内核会自动扩容。而现在 size 已经没有这种语义了,但是调用者调用时 size 依然必须大于 0,以保证后向兼容性。
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
向 epfd 对应的内核epoll 实例添加、修改或删除对 fd 上事件 event 的监听。op 可以为 EPOLL_CTL_ADD, EPOLL_CTL_MOD, EPOLL_CTL_DEL 分别对应的是添加新的事件,修改文件描述符上监听的事件类型,从实例上删除一个事件。
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
当 timeout 为 0 时,epoll_wait 永远会立即返回。而 timeout 为 -1 时,epoll_wait 会一直阻塞直到任一已注册的事件变为就绪。当 timeout 为一正整数时,epoll 会阻塞直到计时 timeout 毫秒终了或已注册的事件变为就绪。因为内核调度延迟,阻塞的时间可能会略微超过 timeout 毫秒。
Epoll运作流程:
- 进程先通过调用
epoll_create来创建一个epoll文件描述符(对应上图中EpollEventLoop中的epollFD)。epoll通过mmap开辟一块共享空间,该共享空间中包含一个红黑树和一个链表(对应上图epollFD中对应的Shared space)。 - 进程调用
epoll的epoll_ctl add,把新来的链接的文件描述符放入红黑树中。 - 当红黑树中的
fd有数据到了,就把它放入一个链表中并维护该数据可写还是可读。 - 上层用户空间(通过
epoll``_``wait)从链表中取出所有fd,然后对其进行读写数据。
4.2.6.4 NettyTransceiver初始化
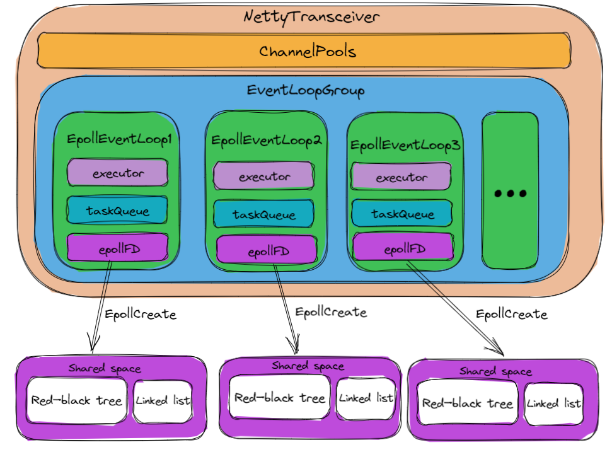
当RestClient刚完成初始化时,NettyTransceiver也刚完成初始化,其初始化主要包含下面两部分:
- 初始化
ChannelPools,刚初始化的ChannelPools为空,其内部不含有任何ChannelPool。 - 初始化
EpoolEventLoopGroup,EpoolEventLoopGroup包含多个EpoolEventLoop。每个EpoolEventLoop都包含下面这三个部分:executor:真正执行任务的线程。taskQueue:任务队列,用户要执行的任务将被加入到该队列中,然后再被executor执行。epollFD:epoll的文件描述符,在EpoolEventLoop创建时,调用epoll_create来创建一个epoll的共享空间,其对应的文件描述符就是epollFD。
4.2.6.5 NettyTransceiver发送请求
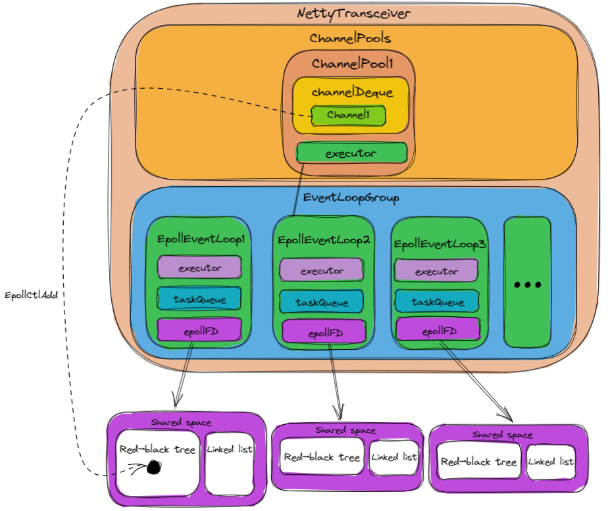
当第一次发送请求时:NettyTransceiver将会为该Server host创建一个ChannelPool(如上图中的ChannelPool1),并缓存到channelPools中(默认10分钟内该Server host没有请求则视为缓存过期,其对应的ChannelPool将被从channelPools中删除)。ChannelPool在初始化时,主要包含下面两部分:
-
初始化
channelDeque,用于缓存channel,获取channel就是从channelDeque中拿出一个channel。 -
在
Event``LoopGroup中选定一个Event``Loop作为executor,该executor用来执行获取连接等操作。之所以ChannelPool需要一个固定的executor来执行获取连接等操作,是为了避免出现多个线程同时获取连接的情况,从而不需要对获取连接的操作进行加锁。ChannelPool初始化完成后,则将由executor从ChannelPool中获取channel,初次获取时,由于ChannelPool中还没有channel,则将初始化第一个channel,channel的初始化步骤主要包含下面几步: -
创建连接,将连接封装为
channel。 -
将
channel对应的连接通过epoll_ctl add方法加入到EpollEventLoopGroup中的一个EpollEventLoop的epollFD对应的共享空间的红黑树中。 -
将
channel放到对应ChannelPool的channelDeque中。 初始化channel完成后,executor则将初始化好的channel返回,由绑定该channel的EpollEventLoop(即初始化channel第二步中所选定的EpollEventLoop)继续执行发送请求数据的任务。
4.2.6.6 NettyTransceiver接收响应
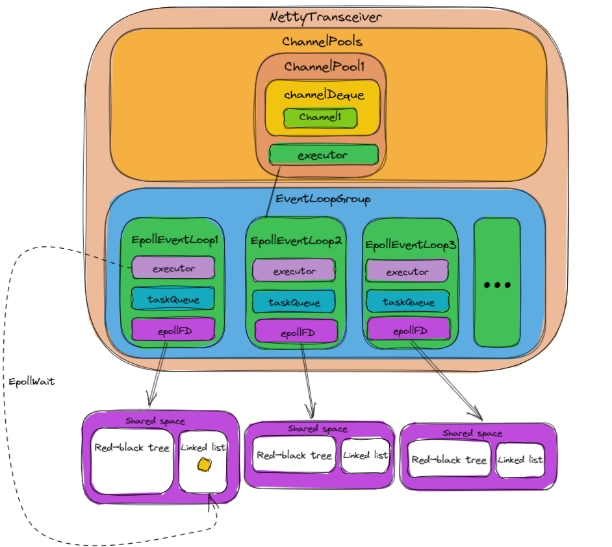
当服务端发送响应时,操作系统将把epollFD对应的共享空间中红黑树中连接的fd移动到链表中,这时当EpollEventLoop调用epoll_wait命令时,将会获取到准备好的fd,从而获取到准备好的channel,最终通过读取并解码 channel 中的数据来完成response的解析。
4.2.7 线程模型
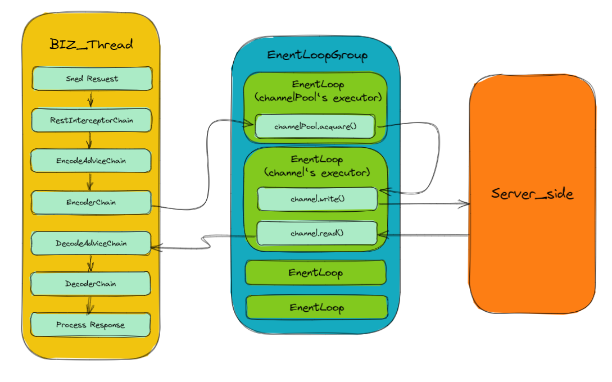
4.2.7.1 线程模型的进一步优化
上面的线程模型为我们当前版本的线程模型,也是Netty自带连接池的线程模型。但是这种线程模型的性能一定是最高的吗?
这个问题的答案应该是否定的,因为尽管 ChannelPool 中指定一个 EventLoop 作为 executor 来执行获取 Channel 的操作可以使得 获取Channel 的过程无多线程争抢,但是却引入了下面这两个问题:
-
获取
Channel到Channel.write()之间大概率会进行一次EventLoop切换 (有可能会将 获取Channel与Channel.write()分配到同一个EventLoop,如果分配到同一个EventLoop,则不需要进行EventLoop切换 ,所以这里说大概率会切换),这次切换是有一定的性能成本的。 -
EventLoopGroup中的EventLoop任务分配不均匀。因为channelPool中获取连接的那个EventLoop在获取连接的同时还要处理数据的收发,比其他EventLoop多做一些工作,该EventLoop也成为了性能瓶颈点。在我们实际测试当中,也的确发现有一个EventLoop的线程CPU利用率较其它EventLoop更高一些。 那么更优越的线程模型是怎样的呢?通过上面的分析,我们觉得它应该要满足下面两点: -
获取
Channel到Channel.write()之间无线程切换。 -
每个
EventLoop的任务分配均匀。 基于我们的需求,我们可以得出最佳的结构模型与线程模型应该为下面这种:
优化后的结构模型:
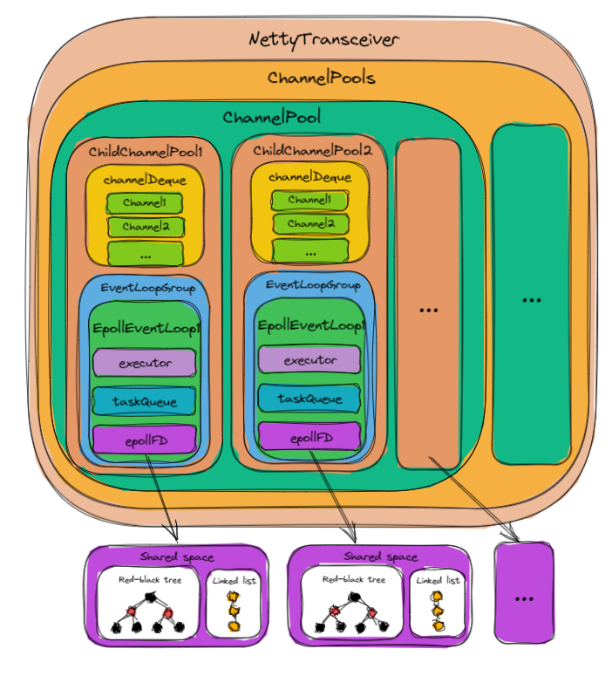
如上图所示:一个 ChannelPool 由多个 ChildChannelPool 构成(个数 = IO线程个数),一个ChildChannelPool与一个 EventLoopGroup绑定,该EventLoopGroup仅含有一个 EventLoop (即一个ChildChannelPool对应一个EventLoop)。
优化后的线程模型:
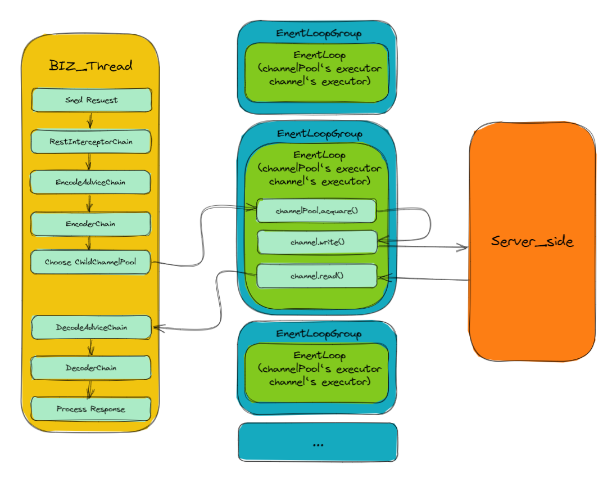
如上图所示:先在业务线程中执行一些操作并获取 ChannelPool ,及选取一个 ChildChannelPool (选取的实现类似于 EventLoopGroup.next()实现,其保证了ChildChannelPool 的均匀分配),然后通过 ChildChannelPool来获取 Channel (该过程在ChildChannelPool 对应的 EventLoop中执行),然后调用Channel.write() (该过程也在ChildChannelPool 对应的 EventLoop 中执行) 。
上述过程巧妙的达成了我们一开始所需要的高性能线程模型的两点:
- 获取
Channel到Channel.write()之间无线程切换 —— 由于ChildChannelPool中的EventLoopGroup仅有一个EventLoop,其创建的Channel也只能绑定该EventLoop,因此获取Channel与Channel.write()都只能在该EventLoop种执行,从而没有了线程切换。 - 每 个
EventLoop任务分配均匀 —— 由于ChildChannelPool是被均匀地从ChannelPool中获取的(该过程与EventLoopGroup.next()的过程类似),而一个ChildChannelPool刚好对应了一个EventLoop,从而使得请求任务被均匀分配。 实践中我们也通过一个Demo进行了测试:发现采用上面这种线程模型与结构模型,使得RestClient的性能在当前版本的基础上又提升了20%左右。预计下个版本中RestClient将会提供上面这种线程模型与结构模型。
5 其它性能优化的一些设计
5.1 Netty
RestClient基于Netty编写,Netty自带的一些高性能特性自然是RestClient高性能的基石,Netty常见特性均在RestClient中有所运用:
EpollChannel&ChannelPoolEventLoop&EventLoopGroupByteBuf&PooledByteBufAllocatorFuture&PromiseFastThreadLocal&InternalThreadLocalMap- …
其中:
Epoll、Channel&ChannelPool、EventLoop&EventLoopGroup我们在该篇文档的结构设计部分已经有过讲解,这里不再对其做过多解释,下面我们主要来看看其它几个部分:
5.1.1 ByteBuf & PooledByteBufAllocator
Netty使用了即易于使用又具备良好性能的ByteBuf来替代ByteBuffer。这里不对ByteBuf进行详细的介绍,主要简单介绍RestClient中如何利用ByteBuf来提高性能以获得更好地用户体验:
- 发送请求时,使用
PooledByteBufAllocator来分配ByteBuf,其池化了ByteBuf的实例以提高性能并最大限度地减少内存碎片。 - 接收响应时,使用
CompositeByteBuf,它提供了一个将多个缓冲区表示为单个合并缓冲区的虚拟表示,减少了当响应分批次到来时聚合响应产生的不必要地数据拷贝。
5.1.2 Future & Promise
Future & Promise 为Netty异步的基石,这里不对Future & Promise 进行详细的介绍,主要介绍RestClient中对于Future & Promise 一些相关的技术上取舍。
RestClient利用Future & Promise来实现数据包收发时的异步,并在面向用户时将Future & Promise转化成CompletionStage。由此实现了从数据包收发 到用户编解码的整个请求链路的异步化。
5.1.3 WhyCompletionStage,Not Future & Promise?
CompletionStage是Java8新增的一个接口,用于异步执行中的阶段处理,其大量用在Lambda表达式计算过程中,目前只有CompletableFuture一个实现类。
比起Netty的Future & Promise,Java开发者更加熟悉CompletionStage,且CompletionStage的接口功能也更加强大,用户可以借其更加灵活地实现业务逻辑。
5.1.4 Why CompletionStage,Not CompletableFuture?
之所以使用CompletionStage而不使用CompletableFuture。是因为 CompletionStage 是接口,而CompletableFuture为 CompletionStage 的实现,使用 CompletionStage 更符合面向接口编程的原则。同时用户也可以使用CompletionStage.toCompletableFuture()来将CompletionStage转化为CompletableFuture。
5.1.5 How To Combine Future & Promise With CompletionStage?
在用户调用请求发送时,我们构建了一个CompletionStage,并在执行Netty处理请求与响应逻辑返回的Future中增加Listener,在该Listener中结束CompletionStage。通过这样实现了将 Future & Promise 与 CompletionStage 结合,从而实现整个请求链路的异步化。
对这块感兴趣的用户可以查看io.esastack.httpclient.core.netty.HttpTransceiverImpl中的handle()方法,该方法中完成了 Future到CompletionStage的转化。
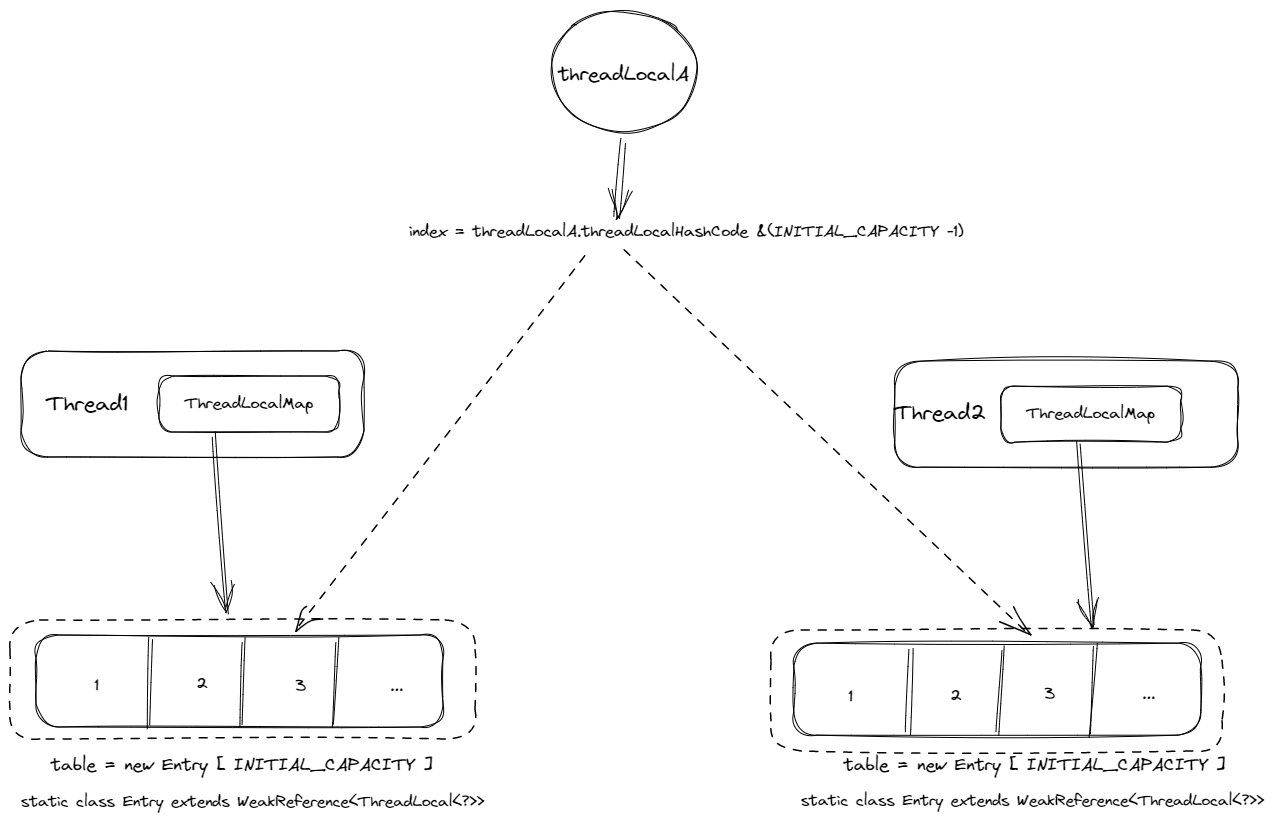
5.1.6 FastThreadLocal&InternalThreadLocalMap
FastThreadLocal通过将ThreadLocal中使用哈希结构的ThreadLocalMap改为了直接使用数组结构的InternalThreadLocalMap。ThreadLocal与FastThreadLocal结构图大致如下:
ThreadLocal结构图
FastThreadLocal结构图
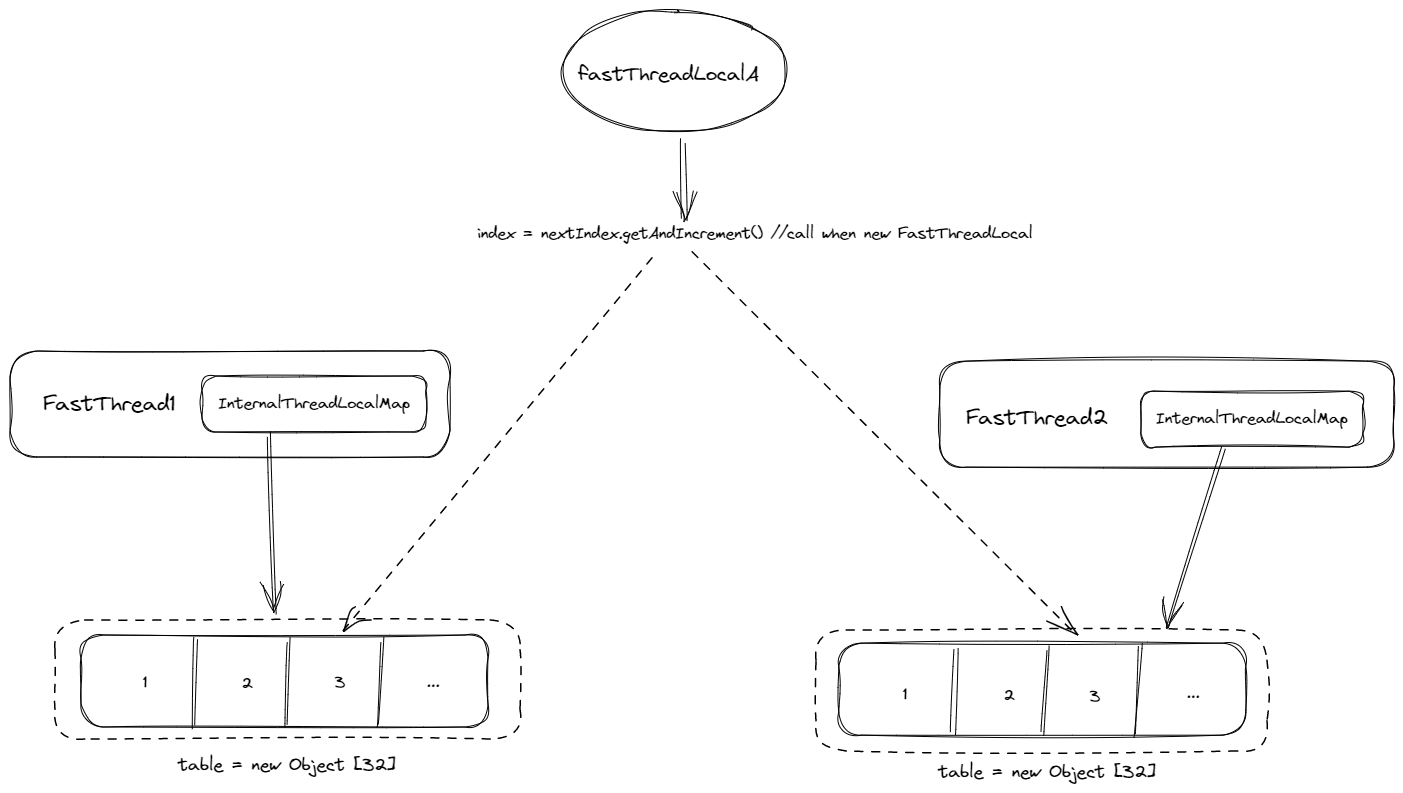
如上图所示,比起ThreadLocalMap,InternalThreadLocalMap直接根据 index 来获取值、设置值的做法更加简单,且直接使用数组的复杂度更低(虽然 ThreadLocalMap也是数组结构,但是其在数组的存取操作外还封装了大量hash计算以及防止hash碰撞的相关操作)。因此FastThreadLocal获得了更高的性能。
RestClient中均使用FastThreadLocal代替ThreadLocal以获取更高的性能。
5.2 Encode & Decode
与大多数Http客户端框架不同,RestClient不仅支持将Java对象Encode成byte[],还支持将Java对象Encode成其他底层Netty支持的对象,如:File、MultipartBody等,未来还将会支持ChunkInput用来支持将请求体比较大的请求分块发送。
之所以这么设计,是因为如果我们仅仅支持将Java对象Encode成byte[],那么当Encode后的byte[]数据过大时,将会出现OutOfMemoryException。用户在发送大文件或者本身请求体较大的请求时,都会出现这个问题。
为了解决这个问题,RestClient通过让用户可以将Java对象Encode成File或者ChunkInput来解决这一类问题。当用户将Java对象Encode成File时,RestClient将会借助底层的Netty使用NIO以零拷贝的方式发送文件,避免了OOM的同时又减少了数据的多次拷贝。
同理当用户将Java对象Encode成ChunkInput时,RestClient将会分块发送数据,避免数据一次性全部加载进内存,从而避免OOM的情况。(PS:ChunkInput当前版本暂不支持,但已留出扩展点,将在下一版本支持)
Decode时也做了同样的优化,由于原理相同这里就不再展开讲解了。
6. 结语
尽管RestClient主要只涉及发起请求这个简单的功能,但是“麻雀虽小,五脏俱全”,它考虑到了性能优化的方方面面,同时在 接口设计、代码整洁、功能完善 几个方面上也尽量做到了毫不妥协。
它还是一个年轻的项目,欢迎各路技术爱好者们加入,一同探讨学习与进步。